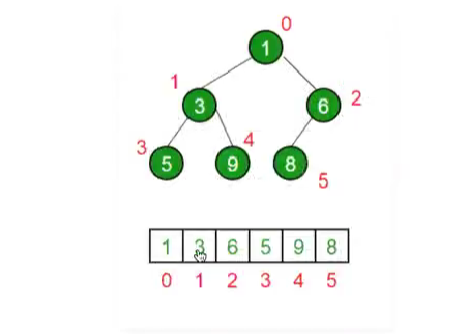
arraylist: 两个都可以表示list。 像是class的样子,只能add加法。
array 和 arraylist接口不一杨
interface和 右边的 object:
eg; List<String> al=new ArrayList<String>
List<String> al2=new LinkedList<String>
举例:
List<String> al=new ArrayList<String>
al=new LinkedList<String>重新赋值也可以,都是list。
但是
ArrayList<String> al=new ArrayList<String>
al=new LinkedList<String>就会报错。
所以说左边最好写成List泛用性大点,一种coding习惯。
可以看tutorial去学习arraylist的具体操作,add change remove 等等和new一个arraylist
- Hashmap: <key,value>,key格式不定
array is a special type of Hashmap:<position, value>
暴力搜索O(e^n),排列组合是n!
eg. a=[2,4,56,7,7,8,7]
Hashmap:知道key求value:O(1),想知道value-》index,可以create一个hashmap。
hashmap的用法可以网上:new, hashmap.keyset
eg: for (integer key : amap.keyset){} for的一个用法
for( entry <integer,String> entry: a.entryset){} 每一个entry是《key,value》,重新创造类也可以
API是什么????get,post,put,delete
用法举例:a.putIfAbsent(key,value),就是如果不存在这个key,就push,也可以用if(a.containKey(key1)) {a.put(key1,value)}。省时用法
hashmap原理:视频 how hashmap works in Java: www.youtube.com/watch?v=c3RVW#KGIIE 48.52秒。 面试可能会问
其实hashmap不是严格O(1),比如和inputsize有关,如果input string很长为n,那就是O(n),如果input长度是一个list,长度n,内部元素长度1,那hashmap长度也是O(1).
所以回答时间复杂度是考虑input size
eg. 10万个数,2万个和key1有关(linklist),所以复杂度也算是O(n)。算是实际实现问题
如果用2茶树,O(log(n)),java 8的优化。
leetcode 刷题,算法面试流程:
1.可以一边问面试官requirement,理解题目意思,
2. walk through examples ,复杂度之类的。
3.还可以问面试官自己的大致思路make sense么
4. 得到认可的话就可以开始coding。
5.还剩余时间的话:
a.面试官可能会问follow question。(一般不需要codng,给思路就可以)
b.可能还存在一些bug或者特殊情况没考虑,面试馆可能让你过一遍代码根据example,来debug。但也不一定有bug。
但2,3步可能会占挺多的时间,不要很担心,因为没思路不行
思路:
search的方法:sorted list的话可以二分法,o(log(n)) , hashmap: O(1)。
walk through example,自己改一下限制条件然后看看思路怎么样
语法问题忘记了的话可以新开个窗口搜一下或者问一下能不能搜一下用法
2 pointers正方向反方向走O(n^2)
比如sorted array(小->大),如果add后大于target那么右指针往左走,因为要缩小求和就一个for(i, j=len-i-1;i<j;)就可以了。
for可以两个变量,也可以把一个变量写到外面,因为要考虑左右指针的移动,多以i++,j--可以for内部if判断
也可以用while(i<size && j>=0) if 求和小于target,左pointer右走,大于右pointer左走。等于return
但是不是sorted的话要先做sorted在写思路,一般情况下sort函数O(nlogn)
需知道solution的时间和空间复杂度;
如果面试官提醒有O(n)那么就不要sort了
看看hashmap
如果知道元素i和target,那么可以看看能不能找到另外一个差值数在不在里面,看看在哪里,所以要用hashmap(这是思路逻辑而不是知道答案上来就说hashmap)
eg.HashMap<Integer, Integer> map=new Hashmap< >(); (可以省略,因为前面写了)
for建立hashmap O(n)
if map.containKey(target-num[i])存在就return,不存在就下一个num[i] O(N)
空间是O(n),因为有hashmap。牺牲空间换了时间
窍门:如果没时间写某个functoin比如binary search,可以写comment和跟面试官说一下,然后不细写
固定一个数,然后利用two sum
作业相似题: