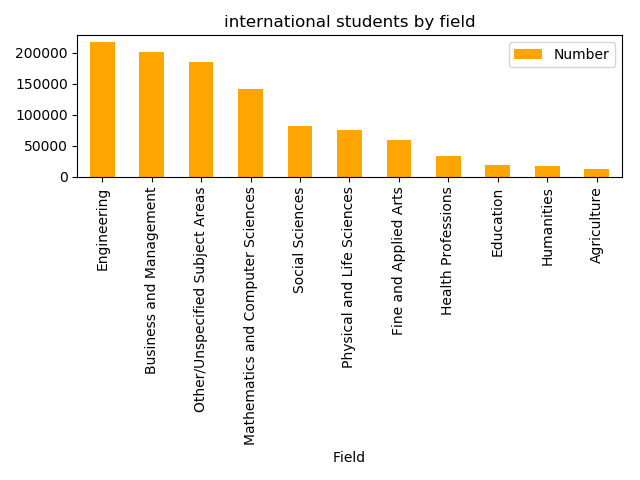
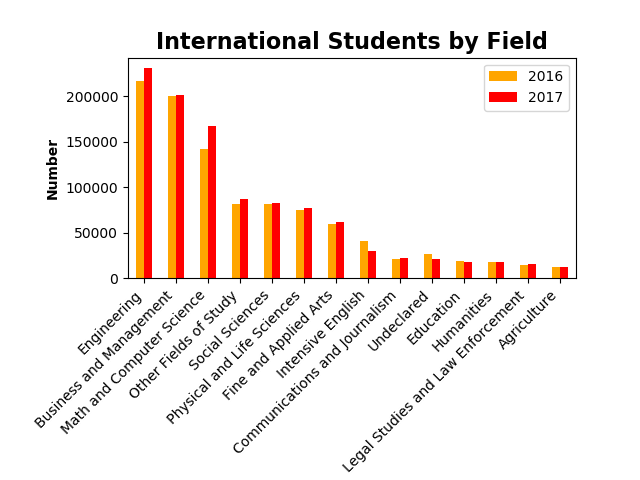
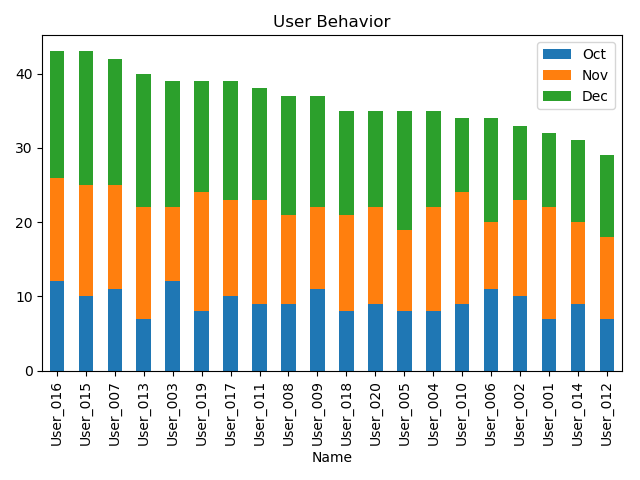
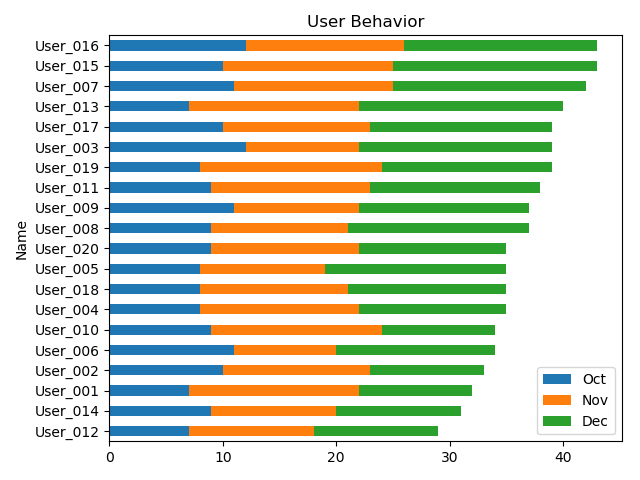
Series
在pandas里面,行和列都可以用一种数据结构Series来表示。
1. 如何生成一个序列对象:
import pandas as pd
s1 = pd.Series()
注:该序列对象为空
2. Series里面几个比较重要的属性
- Series.data (以后将被禁用)
- Series.name
- Series.index
Dictionary 字典
Dictionary是由一系列的keys,values, pairs组成的。
1. 如何生成一个Dictionary
import pandas as pd
d = {'x':100,'y':200,'z':300}
注:
- 'x', 'y', 'z' 是字典d的keys。
- 100, 200, 300 是字典d的values。
2. Dictionary 里的keys, values
d={'x':100,'y':200,'z':300}
print(d.keys())
print(d.values())
得到结果;
dict_keys(['x', 'y', 'z'])
dict_values([100, 200, 300])
d={'x':100,'y':200,'z':300}
print(d['x'])
得到结果
100
创建Series的两种方法:
1. 通过Dictionary来创建Series
Code:
d={'x':100,'y':200,'z':300}
s1 = pd.Series(d)
注:
加入后对应的转换关系:
Dictionary Series
keys --------> index
values ---------> data(not available)
验证一下对应关系如下:
d={'x':100,'y':200,'z':300}
s1 = pd.Series(d)
print(s1.index)
print(s1)
得到结果
Index(['x', 'y', 'z'], dtype='object')
x 100
y 200
z 300
2. 通过分别指定data和index来创建Series
s1=pd.Series([100,200,300],index=['x','y','z'])
print(s1.index)
print(s1)
得到结果
Index(['x', 'y', 'z'], dtype='object')
x 100
y 200
z 300
通过DataFrame来定义Series的行和列
Series本身不具体行和列的属性,但可以通过DataFrame来指定。Series加入到DataFrame的方式不同,其对应的行列也不同,
----复习一下DataFrame语句------------------
pandas.DataFrame(columnName:columnData)
----复习结束---------------------------------
首先创建三个Series
import pandas as pd
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([1,2,3],index=[1,2,3],name='B')
s3 = pd.Series([1,2,3],index=[1,2,3],name='C')
注:这里每一个Series都包含了data,index,name三个完整的属性。
1. 通过字典的方式加入DataFrame
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([1,2,3],index=[1,2,3],name='B')
s3 = pd.Series([1,2,3],index=[1,2,3],name='C')
df=pd.DataFrame({s1.name:s1, s2.name:s2, s3.name:s3})
注:转换后的对应关系
Series Dictionary DataFrame
S1.name ---> Dic.Keys---> columnName
S1.data ----> Dic.Values--->columeData
打印后的到结果
A B C
1 1 1 1
2 2 2 2
3 3 3 3
2. 通过list的形式加入到DataFrame
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([1,2,3],index=[1,2,3],name='B')
s3 = pd.Series([1,2,3],index=[1,2,3],name='C')
df=pd.DataFrame([s1,s2,s3])
注:
这里的series在DataFrame里面是以行的形式存在的,name成立index
打印后得到结果
1 2 3
A 1 2 3
B 1 2 3
C 1 2 3