
students['2017'].sort_values(ascending=True).plot.pie(fontsize=6,startangle=-270)
可以用在乱序的情况

students['2017'].sort_values(ascending=True).plot.pie(fontsize=6,startangle=-270)
可以用在乱序的情况
字符串前加f是用于格式化字符串的,
print(f'#{row.ID}student{row.Name}has an invalid score{row.Score}.')
就相当于
print('# %d student{row.Name}has an invalid score %s.' % (row.ID,row.Score))
具体上网搜一下python 字符串格式化的三种方法就好了
https://www.jianshu.com/p/2d49cb87626b
对于group详细的解析
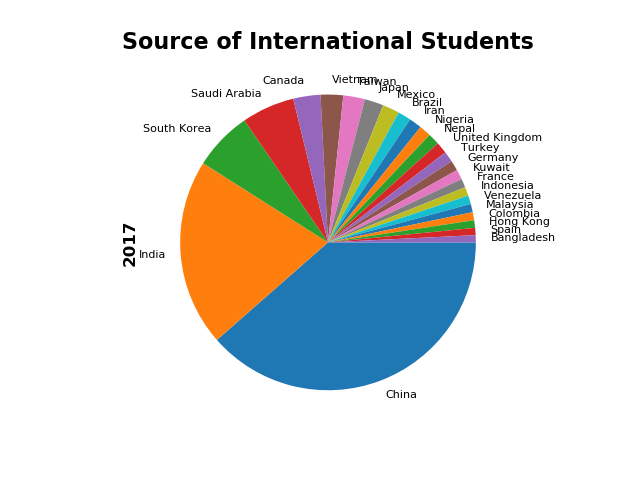
任务12:绘制饼图
绘制饼图是针对一个seriers
students['2017'].plot.pie(fontsize=8, counterclock=False)
注:counterclock=False:顺时针排列
本节代码:
import pandas as pd
import matplotlib.pyplot as plt
students = pd.read_excel('C:/Temp/Students.xlsx', index_col='From')
print(students)
students['2017'].plot.pie(fontsize=8, counterclock=False)
plt.title('Source of International Students', fontsize=16, fontweight='bold')
plt.ylabel('2017', fontsize=12, fontweight='bold')
plt.show()
打印结果:
Rank 2016 2017
From
China 1 328547 350755
India 2 165918 186267
South Korea 3 61007 58663
Saudi Arabia 4 61287 52611
Canada 5 26973 27065
Vietnam 6 21403 22438
Taiwan 7 21127 21516
Japan 8 19060 18780
Mexico 9 16733 16835
Brazil 10 19370 13089
Iran 11 12269 12643
Nigeria 12 10674 11710
Nepal 13 9662 11607
United Kingdom 14 11599 11489
Turkey 15 10691 10586
Germany 16 10145 10169
Kuwait 17 9772 9825
France 18 8764 8814
Indonesia 19 8727 8776
Venezuela 20 8267 8540
Malaysia 21 7834 8247
Colombia 22 7815 7982
Hong Kong 23 7923 7547
Spain 24 6640 7164
Bangladesh 25 6513 7143
d
import pandas as pd
df=pd.DataFrame[{'ID':[1,2,3],'Name':['Tim','Victor','N}]
df.to_excel('C:/Temp/output.xlsx')
print('Done!')
import pandas as pd
people=pd.dread_excle('C:/Temp/people.xlsx')
print(people.shape)
print(people.columns)
print('==================')
print(people.tail(3))
一、涉及知识点
1、Excel和pandas创建excel格式的数据源
2、数据格式有很多,常见的如下:CSV文件、数据库表格、文件格式(Excel、PDF、Word等)、HTML文件、JSON文件、文本文件、XML文件
二、遇到的问题及原因
1、pandas库找不到(AttributeError: module 'pandas' has no attribute 'DataFrame')
原因:1)未安装pandas库
2)pycharm中解释器配置错误(项目多时需要配置虚拟环境,每个虚拟环境中挂载的库都不一样,pycharm的setting中会有默认的配置,需检查是否错误)
一、涉及知识点
1、pandas读取已经存在的Excel文件
2、涉及的BIF操作:
df=pd.read_excel('F:/sdf/sdf/output.xlsx',header=None)
pd.to_excel('F:/sdf/sdf/output1.xlsx')
df.shape
df.columns
df.header(5)
df.tail(5)
二、问题点
1、读取xls文件异常(xlrd.biffh.XLRDError: Unsupported format, or corrupt file: Expected BOF record; found b'Test Tim')
原因:源文件损坏,或者格式有问题(虽然是以.xls结尾,但实际上内容格式有问题的)
笔记,不错。
不能直接贴屏?!
图片要用文件上传模式,一般。
import pandas as pd
# 蔓藤教育,pandas操作excel的行和列等
import pandas as pd
# 创建一个序列,在pandas中,数据帧DataFram和序列Series是最基本的数据结构
# pandas中的序列的第一种方法,由python中的字典改变而来
d = {'x': 100, 'y': 200, 'z': 300}
print(d)
s1 = pd.Series(d)
# 创建序列的第二种方法
L1 = [100, 200, 300]
L2 = ['x', 'y', 'z']
s2 = pd.Series(L1, index=L2)
#s2.to_excel('output3.xlsx', header=None)
# 序列在excel中可能是行,也可能是列,根据传递进DataFrame中序列的方法不同,在excel中呈现行或列不同
s3 = pd.Series([1, 2, 3], index=[1, 2, 3], name='A')
s4 = pd.Series([10, 20, 30], index=[1, 2, 3], name='B')
s5 = pd.Series([100, 200, 300], index=[1, 2, 3], name='C')
# 当以字典形式将序列传递进数据帧时,在excel中以列呈现
# 创建ExcelWriter对象实现向excel中不同sheet中追加写入内容,否则会被覆盖
writer = pd.ExcelWriter('output.xlsx')
df = pd.DataFrame({s3.name: s3, s4.name: s4, s5.name: s5})
#df.to_excel('output3.xlsx', sheet_name='sheet1')
df.to_excel(writer, sheet_name='字典传入为列')
# 当以列表List形式传入时,以行的形式存在
df1 = pd.DataFrame([s3, s4, s5])
#df1.to_excel('output3.xlsx', sheet_name='sheet2')
df1.to_excel(writer, sheet_name='列表传入为行')
writer.save()
在执行books['Date'].at[i] = start + timedelta(days=i)时会报错
unsupported type for timedelta days component: numpy.int64
最终修改为books['Date'].at[i] = start + timedelta(days=int(i))可以正常运行