任务12:绘制饼图
绘制饼图是针对一个seriers
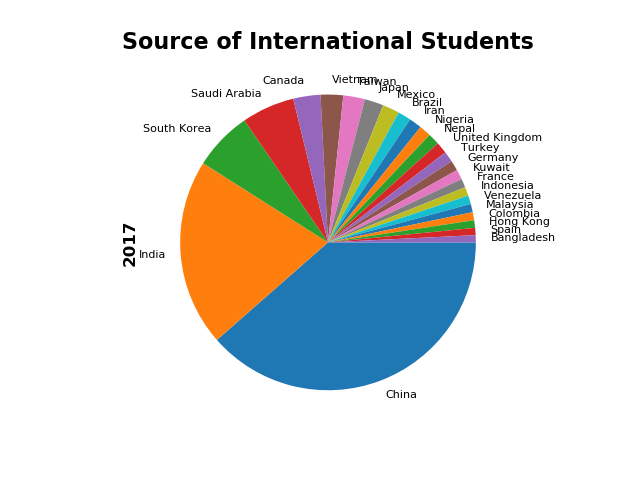
students['2017'].plot.pie(fontsize=8, counterclock=False)
注:counterclock=False:顺时针排列
本节代码:
import pandas as pd
import matplotlib.pyplot as plt
students = pd.read_excel('C:/Temp/Students.xlsx', index_col='From')
print(students)
students['2017'].plot.pie(fontsize=8, counterclock=False)
plt.title('Source of International Students', fontsize=16, fontweight='bold')
plt.ylabel('2017', fontsize=12, fontweight='bold')
plt.show()
打印结果:
Rank 2016 2017
From
China 1 328547 350755
India 2 165918 186267
South Korea 3 61007 58663
Saudi Arabia 4 61287 52611
Canada 5 26973 27065
Vietnam 6 21403 22438
Taiwan 7 21127 21516
Japan 8 19060 18780
Mexico 9 16733 16835
Brazil 10 19370 13089
Iran 11 12269 12643
Nigeria 12 10674 11710
Nepal 13 9662 11607
United Kingdom 14 11599 11489
Turkey 15 10691 10586
Germany 16 10145 10169
Kuwait 17 9772 9825
France 18 8764 8814
Indonesia 19 8727 8776
Venezuela 20 8267 8540
Malaysia 21 7834 8247
Colombia 22 7815 7982
Hong Kong 23 7923 7547
Spain 24 6640 7164
Bangladesh 25 6513 7143